[#85349] [Ruby trunk Bug#14334] Segmentation fault after running rspec (ruby/2.5.0/erb.rb:885 / simplecov/source_file.rb:85) — pragtob@...
Issue #14334 has been updated by PragTob (Tobias Pfeiffer).
3 messages
2018/02/02
[#85358] Re: [ruby-cvs:69220] nobu:r62039 (trunk): compile.c: unnecessary freezing — Eric Wong <normalperson@...>
nobu@ruby-lang.org wrote:
5 messages
2018/02/03
[#85612] Why require autoconf 2.67+ — leam hall <leamhall@...>
Please pardon the intrusion; I am new to Ruby and like to pull the
6 messages
2018/02/17
[#85634] [Ruby trunk Bug#14494] [PATCH] tool/m4/ruby_replace_type.m4 use AC_CHECK_TYPES for HAVE_* macros — normalperson@...
Issue #14494 has been reported by normalperson (Eric Wong).
3 messages
2018/02/19
[#85674] [Ruby trunk Feature#13618] [PATCH] auto fiber schedule for rb_wait_for_single_fd and rb_waitpid — matz@...
Issue #13618 has been updated by matz (Yukihiro Matsumoto).
5 messages
2018/02/20
[#85686] Re: [Ruby trunk Feature#13618] [PATCH] auto fiber schedule for rb_wait_for_single_fd and rb_waitpid
— Eric Wong <normalperson@...>
2018/02/20
matz@ruby-lang.org wrote:
[#85704] Re: [Ruby trunk Feature#13618] [PATCH] auto fiber schedule for rb_wait_for_single_fd and rb_waitpid
— Koichi Sasada <ko1@...>
2018/02/21
On 2018/02/20 18:06, Eric Wong wrote:
[ruby-core:85424] [Ruby trunk Feature#14370] Directly mark instruction operands and avoid mark_ary usage on rb_iseq_constant_body
From:
tenderlove@...
Date:
2018-02-06 00:36:37 UTC
List:
ruby-core #85424
Issue #14370 has been updated by tenderlovemaking (Aaron Patterson). File direct_marking.diff added ko1 (Koichi Sasada) wrote: > > Approximately 60% of the instruction sequences have 0 markable objects. Those 60% account for 35% of the total iseq_encoded that needs to be walked: > > It seems many extra data we are holding. If we shrink such extra space (capa) just after compiling, it can reduce memory. I tried this approach to compare, here is the patch I used: https://gist.githubusercontent.com/tenderlove/f7fe6e09d6f9cacd3299abdd39fb65b7/raw/9b7dd3718278f7be0eb18bedf94590573e313ab2/resize_array.diff This results in slightly more memory usage than directly marking iseq in my test (57300896 bytes vs 57112281 bytes). Unfortunately this patch also made more calls to malloc / free in order to allocate the smaller array. Maybe there is a way to do this in-place? > Of course, Aaron's approach helps more (because we don't need to keep `mark_ary` any more for referencing objects). But it is simple and no computation cost on marking phase. > > Thoughts? I wanted to see what it takes to remove `mark_ary` and what the benefits would be, so I did that too. I found removing the mark array resulted in a 6.6% memory reduction compared to trunk (vs 3% from direct marking). To remove the mark array, first I started marking once results: https://github.com/github/ruby/commit/b85d83613ad37d8c56277a7ac7d9bda69e1d8f67.diff The `once` instruction declares its operand is an inline cache struct, but it's actually a `iseq_inline_storage_entry`, so I had to add a conditional to cast the IC but only for `once` and `trace_once` instructions. Next I was able to remove the mark array: https://github.com/github/ruby/commit/29c95eec9c5ce6a9735169c5d6f1d08343d643d1.diff I added a flag to the iseq to indicate whether or not the iseq has markable objects: https://github.com/github/ruby/commit/fcb70543fcf73216e01634af1cc6e161eec3d2b6.diff After that patch the only iseqs that have performance impact are ones that actually need to be disassembled for marking. Finally, I added a new operand for `once` instructions, then removed the conditionals from the mark / compile function: https://github.com/github/ruby/commit/78ce485d9880e8694d586e93a48429f4aa907c18.diff I ran the same benchmark to compare all four versions: 1. trunk 2. Directly marking 3. Removing the mark array 4. Resizing the mark array 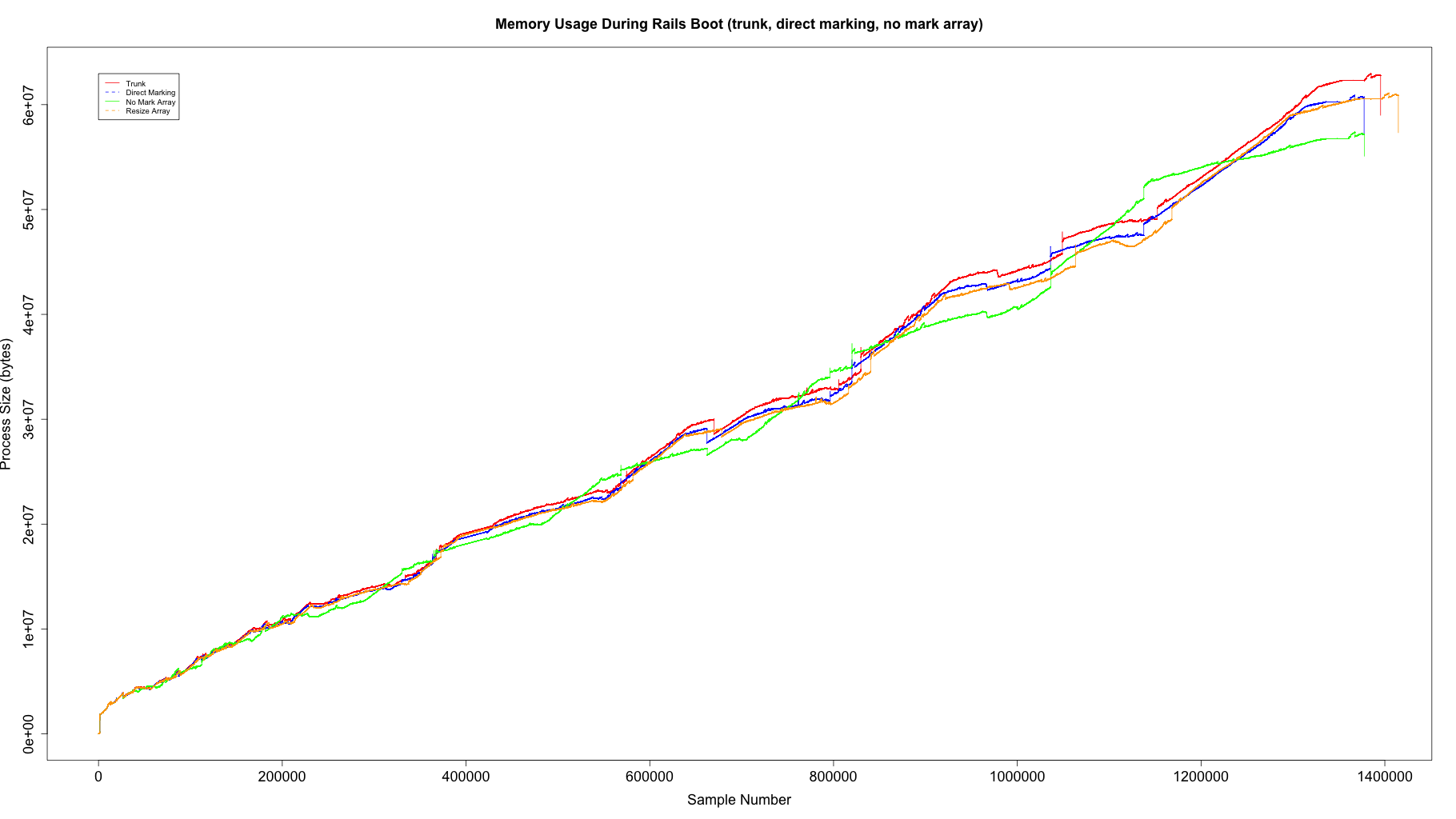 From the graph you can see that resizing the mark array ends up with the same memory usage as direct marking, but takes more `malloc` calls to do it (the X axis is process size at each malloc, so the more samples the more malloc calls). Out of curiosity, I printed `GC.stat` after booting the Rails app for trunk, resizing the array, and removal: ~~~ key trunk resize remove count 46 47 49 heap_allocated_pages 664 656 505 heap_sorted_length 664 656 505 heap_allocatable_pages 0 0 0 heap_available_slots 270637 267387 205847 heap_live_slots 184277 184275 157995 heap_free_slots 86360 83112 47852 heap_final_slots 0 0 0 heap_marked_slots 184194 184192 157912 heap_eden_pages 664 656 505 heap_tomb_pages 0 0 0 total_allocated_pages 664 656 505 total_freed_pages 0 0 0 total_allocated_objects 986460 1005514 951828 total_freed_objects 802183 821239 793833 malloc_increase_bytes 1168 1168 1168 malloc_increase_bytes_limit 16777216 16777216 16777216 minor_gc_count 36 36 39 major_gc_count 10 11 10 remembered_wb_unprotected_objects 1640 1639 1660 remembered_wb_unprotected_objects_limit 3280 3278 3320 old_objects 177699 177482 153681 old_objects_limit 355398 354964 307362 oldmalloc_increase_bytes 1616 1616 2522576 oldmalloc_increase_bytes_limit 16777216 16777216 16777216 ~~~ As expected, removing the mark array decreased the number of allocated pages and the number of live slots. Anyway, I really like the idea of removing the mark array, though I realize this patch is a little complex. I think the savings are worth the change. I've attached an updated diff with all of the changes I've made so far. As a side note, I think we could remove `original_iseq` from the struct / mark array. AFAICT the `original_iseq` slot is just there because `rb_iseq_original_iseq` returns the underlying pointer and something needs to keep it alive. Maybe we could use a callback and keep the reference on the stack? I will send a patch for it so we can discuss on a different ticket. :) ---------------------------------------- Feature #14370: Directly mark instruction operands and avoid mark_ary usage on rb_iseq_constant_body https://bugs.ruby-lang.org/issues/14370#change-70206 * Author: tenderlovemaking (Aaron Patterson) * Status: Open * Priority: Normal * Assignee: ko1 (Koichi Sasada) * Target version: ---------------------------------------- Hi, I've attached a patch that changes rb_iseq_mark to directly mark instruction operands rather than adding them to a mark array. I observed a ~3% memory reduction by directly marking operands, and I didn't observe any difference in GC time. To test memory usage, I used a basic Rails application, logged all malloc / free calls to a file, then wrote a script that would sum the live memory at each sample (each sample being a call to malloc). I graphed these totals so that I could see the memory usage as malloc calls were made:  The red line is trunk, the blue line is trunk + the patch I've attached. Since the X axis is sample number (not time), the blue line is not as long as the red line because the blue line calls `malloc` fewer times. The Y axis in the graph is the total number of "live" bytes that have been allocated (all allocations minus their corresponding frees). You can see from the graph that memory savings start adding up as more code gets loaded. I was concerned that this patch might impact GC time, but `make gcbench-rdoc` didn't seem to show any significant difference in GC time between trunk and this patch. If it turns out there is a performance impact, I think I could improve the time while still keeping memory usage low by generating a bitmap during iseq compilation. There is a bit more information where I've been working, but I think I've summarized everything here. https://github.com/github/ruby/pull/39 ---Files-------------------------------- iseq_mark.diff (6.28 KB) iseq_mark.diff (6.28 KB) iseq_mark.diff (7.26 KB) benchmark_methods.diff (1.23 KB) bench.rb (3.01 KB) direct_marking.diff (18.4 KB) -- https://bugs.ruby-lang.org/ Unsubscribe: <mailto:ruby-core-request@ruby-lang.org?subject=unsubscribe> <http://lists.ruby-lang.org/cgi-bin/mailman/options/ruby-core>